Related Posts

blog
Dealing with the “bad actors” problem
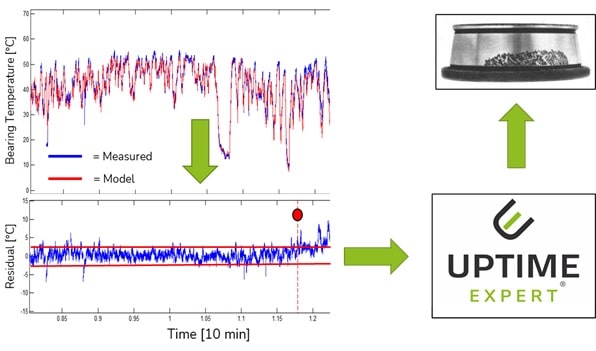
Monitoring and analyzing data for predictive maintenance assumes that ....

blog
The Principles of System Reliability
What makes our lives as part of the techno sphere stressful is its unreliability.

blog
Anomaly detection for condition-based maintenance
How do we find out that something is wrong with the technology - and why...



