Die Standard-Methoden der technischen Zuverlässigkeit sind nicht auf alle Aufgaben der Praxis nützlich anwendbar. Uptime ENGINEERING hat daher im Lauf der letzten Jahre einen umfassenden Satz von speziellen Methoden für den Zuverlässigkeitsprozess entwickelt. Das geschah häufig zur Lösung konkreter Aufgaben im Rahmen von Kundenprojekten. Neuartige Aufgabenstellungen in aktuellen Projekten führen auch aktuell zu einer permanenten Erweiterung der Methoden-Bibliothek.
Der Schwerpunkt liegt auf Methoden der angewandten Statistik und Schädigungs-Physik.
Dabei wird generell ein Design verfolgt, das den durchgängigen Zuverlässigkeitsprozess im Produkt-Lebenszyklus bestmöglich unterstützt. Die Methoden sind daher in Uptime SOLUTIONS in generischer, parametrierter Form implementiert. Sie sind dadurch für alle Anwendungen der Software rasch und ohne Programmierarbeit verfügbar.
Physics of Failure (PoF) ist ein wissenschaftsbasierter Modellierungsansatz zur Bewertung von schädlichen Auswirkungen als Funktion der Betriebsbedingungen. Es wird auf alle Integrationsebenen von Komponenten bis hin zu kompletten technischen Systemen angewendet.
In der wissenschaftlichen Literatur findet sich ein umfangreicher Satz von Modellen für eine Vielzahl von Versagensmechanismen (Arrhenius, Woehler, Manson-Coffin, Norton, etc.). Die Uptime PoF-Modellbibliothek erweitert dieses Set um ein noch breiteres Spektrum an speziellen Fehlermodi. Darüber hinaus wird in der Software Uptime SOLUTIONS PoF auch für die Entwicklung dedizierter Modelle für bestimmte Fehlermodi eingesetzt.
PoF wird während des Produktlebenszyklus eingesetzt. Während der Konstruktion ist PoF der klassische Ansatz zur systematischen Untersuchung der Robustheit gegen verschiedene Ausfallrisiken. In der Produktvalidierung werden PoF-Modelle zur quantitativen Testbewertung angewendet. Dies dient der Optimierung von Tests gegen verschiedene Arten von Ausfallrisiken (Schädigungsrechnung). Das risikofokussierte Flottenmonitoring stützt sich schließlich auf PoF für die Bewertung des tatsächlichen Belastungsintensität und für die Berechnung der Ausfallwahrscheinlichkeit, also der Restnutzungsdauer.
Die Uptime ENGINEERING PoF-Modellbibliothek bewertet die Kinetik schädigender Mechanismen in generischer Form. Sie liefert die Vorlagen für die Anwendung auf verschiedene Sonderfälle in verschiedenen Produkten und Branchen. Die PoF-Modellanwendung erfordert eine Parametrisierung mit der Belastbarkeit der betrachteten Komponenten. Es ist kein umständliches „data-labeling“ oder zeitaufwändiges Modelltraining notwendig. PoF-Modelle sind transparent, Modellannahmen und -grenzen sind von Ingenieuren leicht zu beurteilen. Dies ist insbesondere bei der Anwendung zur Entscheidungsunterstützung von größter Bedeutung.
Die Schädigungsrechnung leitet die Schadensakkumulation aus Lastverläufen ab. Dies wird über Physics of Failure-Modelle ausgeführt, die auf Zeitreihen von Lastdaten angewendet werden. Die Last kann mechanischer, thermischer, chemischer und elektrischer Natur sein. Ein entsprechender Satz von Eingabedaten notwendig, um alle Arten von schädlichen Auswirkungen in einem Produkt abzudecken. Ist die Messung dieser Daten an kritischen Stellen nicht möglich, wird aus globalen Lastdaten über Übertragungsfunktionen („virtueller Sensor“) die lokale Last simuliert.
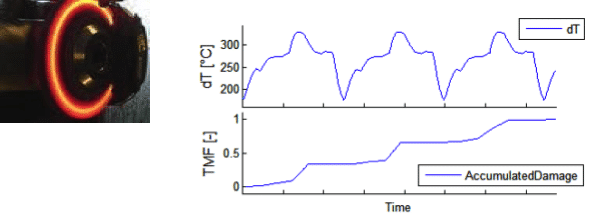
Die Schädigungsrechnung dient der Ermittlung der schädigenden Auswirkungen eines Lastverlaufs. Verschiedene Schädigungsmechanismen werden durch einen entsprechenden Satz von Modellen abgedeckt. In Planungsphasen werden mangles Hardware die notwendigen Input-Zeitreihen simuliert. Messdaten werden ermittelt, sobald Prototypen verfügbar sind.
Schädigungsrechnung ist insbesondere für die Testoptimierung in Bezug auf Referenz-Zyklen nützlich. Sie wird auch für die Testbeschleunigung gegen bestimmte Schädigungsmechanismen verwendet.
Die Schädigungsrechnung liefert einen quantitativen Vergleich der Schadenskinetik für verschiedene Lastverläufe. Vereinfachte Modelle werden sehr früh für die Planung eingesetzt. Eine höhere Genauigkeit wird durch System-Antwort Modellierung oder durch Messung erreicht, die schon während der Design Verifikation durchgeführt wird.
Die meisten der tatsächlichen Zuverlässigkeitsprobleme hängen mit transienten lokalen Spannungen zusammen, die sich aus Gradienten der Last, der Last-Übertragung oder der Belastbarkeit ergeben. Ein bekanntes Beispiel ist die thermische Ermüdung, die durch lokal verzögertes Aufheizen und Abkühlen aufgrund von Gradienten in der thermischen Masse oder Wärmeübertragung entsteht.
Die Schädigungsrechnung für dynamische Arbeitszyklen erfordert die genaue Bestimmung dieser transienten Kinetik. Da solche Messungen schwierig und kostspielig sind, wird die Modellierung der System-Antwort als Ersatz für die permanente Messung verwendet.
Dazu wird ein einmaliges Messprogramm zur Systemreaktion auf Lastwechsel durchgeführt, um eine Übertragungsfunktion zu parametrieren. Sie bildet die beobachtbaren Lastdaten auf die lokale Last unter transienten Bedingungen ab. Dieses Mapping wird in der Folge als „virtueller Sensor“ für alle Arten von Arbeitszyklen verwendet.
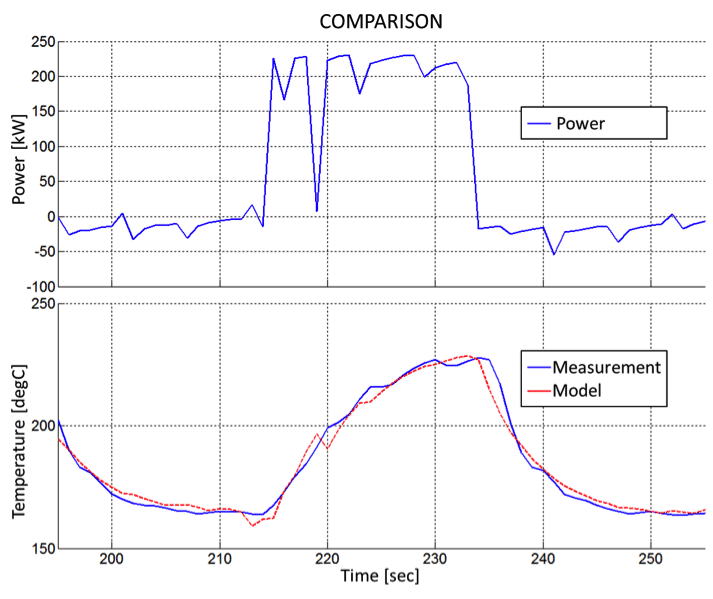
Virtuelle Sensoren werden zur Auswertung von lokalen Lasten unter verschiedenen Arbeitszyklen eingesetzt. Während der Produktentwicklung werden virtuelle Sensoren zur Testbewertung eingesetzt. Beim Flottenmonitoring generieren sie über Residualanalysen den Erwartungs- oder Referenzwert für die Zustandserkennung.
Nach der ersten Messung des Systemverhaltens ist keine zusätzliche Sensorik für weitere Tests oder Lastzyklen erforderlich.
Die System-Antwort Modellierung liefert im Vergleich zum CAE-Ansatz eine hohe Genauigkeit für dynamisches Systemverhalten bei geringem Aufwand. Lastinformationen für verschiedene Positionen innerhalb eines Produkts können ohne Hochfrequenz-Datenermittlung aus globalen Lastdaten abgeleitet werden.
Statistik liefert einen leistungsstarken Satz von Methoden, um Korrelationen aufzudecken und Abhängigkeiten in Datensätzen zu beschreiben. Angewandte Statistik im Reliability Engineering umfasst Zuverlässigkeitsdemonstration und Lebensdauer, Regression und Varianz sowie Datenclustering und grafische Darstellungstechniken.
Im Rahmen der Zuverlässigkeit werden statistische Methoden zur permanenten Überwachung und Analyse von Serienfehlern und zur Überprüfung von Ursachenhypothesen eingesetzt. Ihre Kombination mit Physics of Failure ist der Verwendung einzelner Werkzeuge zur Problemanalyse deutlich überlegen. Während der Entwicklung wird der Grad der Zuverlässigkeitsdemonstration mit statistischen Modellen ausgewertet. Sie werden auf Komponenten ( Reifegraddemonstration) und auf Systemebene (MTBF, MDBF, MTTR usw.) angewendet. Schließlich werden im Flottenmonitoring statistische Analysen von Zeitreihendaten wird zur Mustererkennung eingesetzt, um Indikatoren für abweichendes Systemverhalten zu erkennen.
Angewandte Statistik liefert eine quantitative Beurteilung des Zuverlässigkeits-Status. Sie unterscheidet Qualitäts- von Zuverlässigkeitsproblemen und hilft, ihre Ursachen zu identifizieren.
Statistik bewertet das Potenzial eines Testprogramms für den Zuverlässigkeitsnachweis in Planung und Ausführung.
Statistik modelliert das Systemverhalten und quantifiziert Streubänder. Sie bildet damit die Grundlage für die Erkennung signifikanter Abweichungen. Die statistische Lebensdauermodellierung wird im Rahmen der vorausschauenden Wartung eingesetzt.
Algorithmen für Zustandserkennung unterscheiden zwischen fehlerfreien und geschädigten Systembedingungen. Die fehlerfreie Referenz wird durch System-Antwort Modellierung erzeugt. Es ist für Referenzen zentral, dass die Details des transienten Systemverhaltens korrekt erfasst werden. Das sorgt für hohe Qualität der Zustandserkennun: hohe Erfassungsrate bei niedriger Frequenz von Fehlalarmen.
Die Vielfalt der potenziellen Fehlermodi wird durch einen entsprechenden Satz von Algorithmen überwacht. Ihre Aufgabe ist es, den Beginn einer Schädigung anzuzeigen. Darüber hinaus triggert die Erkennung von Abweichungen die eautomatische modellbasierte Diagnose, von Uptime ENGINEERING für die Problemlösung.
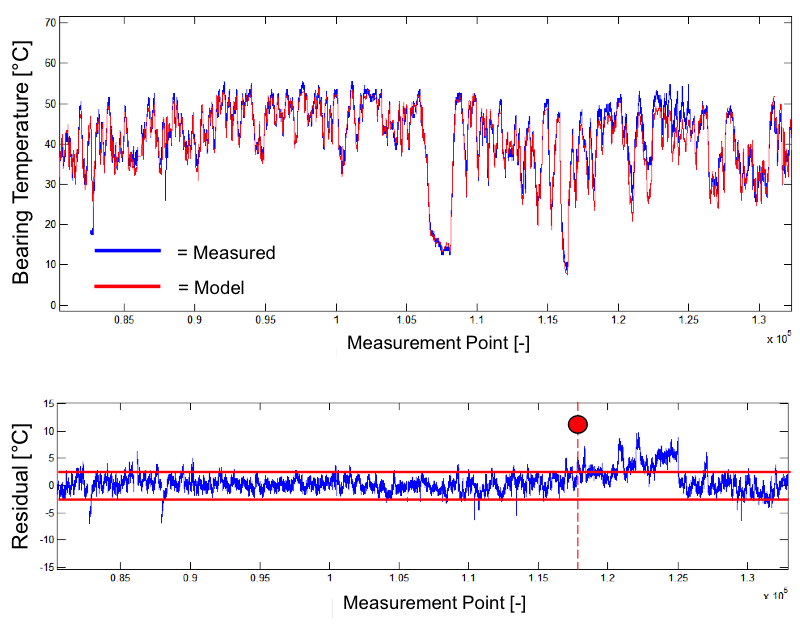
Hochempfindliche Systembeobachtung mittels Residualanalyse liefert Zustandserkennung mit geringer und quantifizierter Fehlerwahrscheinlichkeit. Status-Daten werden als Zeitreihen zusammen mit Meßdaten gespeichert, um sie für die Nachbearbeitung in Kombination mit anderen Arten von Informationen und Flottenüberwachungsdaten („Information-merging“) zur Verfügung zu stellen.
Ein kompakter Satz von Überwachungsalgorithmen überdeckt die Risiko-Landschaft. Volle Nutzung der verfügbaren SCADA-Daten als Input für die Modelle. Sehr geringer Anteil an zusätzlicher Sensorik. Transprente, verständliche Algorithmen. Extrem hohe Detektions-Wahrscheinlichkeit für abweichende Systemeigenschaften unter realistischen Lastbedingungen.
Im Gegensatz zur FMEA – die sich auf die Folgen eines Fehlermodus konzentriert – ermittelt die Ausfallspotenzial-Analyse (APA) die Ursachen und die schädigenden Bedingungen für Ausfälle, die sich im Laufe der Betriebszeit entwickeln. In APA-Workshops wird ermittelt, wie ein technisches System oder eine Komponente während des Betriebs aufgrund von Degradation ausfallen kann. Diese Workshops machen das implizite Wissen von Domänenexperten explizit.
Für Ausfallsmechanismen werden in der APA die schädigenden Betriebsbedingungen ermittelt, ihren Observablen, Indikatoren und kritischen Eigenschaften geklärt. Darüber hinaus werden Test-, Simulations- und Qualitätsaktivitäten zur Minderung dieses Risikos identifiziert. Die APA wird damit zur Plattform für die Definition von Validierungsprogrammen und für die risikoorientierte Flottenüberwachung.
Die Reduzierung der Zuverlässigkeits-Risiken ist der generelle Zweck der APA. Dies wird auf verschiedene Arten realisiert:
Die APA liefert eine transparente und gut strukturierte Wissensbasis zu Zuverlässigkeitsrisiken. Durch den Gebrauch der APA in Projekten entsteht und wächst eine Unternehmensreferenz zu Zuverlässigkeitsrisiken.
APA-Ergebnisse sind während des gesamten Produktlebenszyklus von Nutzen: für die Testbewertung und Optimierung von Validierungsprogrammen, für die Qualitätsspezifikation in Bezug auf Zuverlässigkeit, für die risikoorientierte Flottenanalyse.
Die APA ist der Grundstein für den Zuverlässigkeits-Prozess.
Die Diagnose bestimmt die Ursache eines abweichenden Systemverhaltens, d.h. sie erklärt eine nicht-gesunde Zustandserkennung als Folge eines Schädigungs-Mechanismus. Im Allgemeinen ist dies eine schwierige Aufgabe, da eine Abweichung (z. B. Leistungsminderung) in der Regel nicht spezifisch für eine bestimmte Ursache ist. Ein solcher Indikator bezieht sich typischerweise auf mehrere potenzielle Schädigungsmechanismen. Die endgültige Diagnose erfordert daher zusätzliche Informationen zur Unterscheidung zwischen den Ursachenkandidaten. Dazu dienen zusätzliche Messkanäle, Vor-Ort-Inspektion, Systemreaktion auf kritische Betriebsmodi oder Zeitentwicklung der beobachteten Indikatoren.
Uptime EXPERT führt die Diagnose automatisch durch. Für die Modellierung des „Inferenzprozesses“ wird die Wissensbasis über Fehlermechansmen verwendet. Die Diagnose-Algorithmen korrelieren die Beobachtungen mit den Ursachen – genau so wie ein erfahrener Techniker es macht und wie es in der Ausfallspotenzial-Analyse ermittelt wurde.
Die Ursachendiagnose wird zur Problemlösung verwendet. Sie liefert Vorschläge, wie für die Ursachenermittlung von Fehlern vorzugehen ist. Sie wird in der Flottenüberwachung für die Empfehlung zustandsbasierter Instandhaltungsaufgaben (CBM) angewendet. Darüber hinaus wählt die Diagnose eines Ausfallmechanismus das richtige Schädigungsmodell für die Berechnung der verbleibenden Lebensdauer aus.
Im Gegensatz zu big-data-Analysen liefert die Architektur von Uptime EXPERT eine Erklärungung und die Argumente für Ergebnisse. Dies wird in technischer Sprache bereitgestellt, um eine Transparenz für das zugrunde liegende technische Problem zu gewährleisten.
Im Rahmen der Flottenüberwachung ermittelt Uptime EXPERT automatisch die Ursachen für abweichendes Systemverhalten. Es liefert den Gesundheitszustand des beobachteten Systems. Die durch Diagnosen gewonnenen Erkenntnisse bilden die Grundlage für Risikomanagement und für geeignete Risiko-Reduktiongsmaßnahmen. Diagnose wird zur Optimierung der Instandhaltung im Sinne einer zustandsbasierten und vorausschauenden Instandhaltung eingesetzt (CBM und PDM).
Prognose sagt das Systemverhalten voraus, insbesondere die Ausfallwahrscheinlichkeit, bzw. die Zeit bis zum Ausfall. Uptime ENGINEERING Lebensdauermodelle bewerten dazu den Schädigungsfortschritt in Abhängigkeit von schädigenden Bedingungen. Letztere können sich je nach Schädigungsmechanismus stark unterscheiden (z. B. hohe Temperatur für thermische Alterung vs. Lastwechsel für Ermüdung). Daher müssen prognostische Modelle sorgfältig ausgewählt werden. Dies geschieht durch die Ursachendiagnose, die jeweils vor der Prognose durchgeführt wird.
Eine zweckdienliche Aufwands-Organisation in der CBM erfordert die Prognose der verbleibenden Nutzungsdauer für ein fehlerhaftes Bauteil. Uptime ENGINEERING Lebensdauer-Modelle werden aus Projekten zur Produktvalidierung übernommen. Dies ermöglicht die Fokussierung auf die tatsächlichen Risiken von Systemen.
Die Prognose ist entscheidend fürdie Entscheidungen im Rahmen der risikobasierten Instandhaltung (CBM, PDM). Sie verbessert die Wartungsqualität zu reduzierten Kosten. Auf der Managementebene unterstützt die Prognose das Risikomanagement und die Budgetierung.